



CeCon for Eliminating Spurious Correlations
Bias datasets cause models to learn spurious correlations.
Compared with constructing new counterfactual samples,
we consider that making full use of the samples in the
dataset can also eliminate spurious correlation.
Learning More...
Bias datasets cause models to learn spurious correlations.
Compared with constructing new counterfactual samples,
we consider that making full use of the samples in the
dataset can also eliminate spurious correlation.
Through analytical experiments, we find that the counterexamples in
the dataset can play an important role in avoiding model utilizing
spurious correlation. Inspired by the above conclusion,
we propose counterexample contrastive (Ce-
Con) loss which treats counterexamples as negatives
in contrastive loss. This method utilizes contrastive
learning to pull the samples with different
bias feature in the same class and push the samples
with the same bias feature in different class,
so as to eliminate the spurious correlation caused
by bias. Experimental results show that our proposed
method can achieve state-of-the-art results
when the bias features are known.

Generalization of DNNs on Out-Of-Distribution(OOD)
Learning More...
Deep network models perform excellently on In-Distribution (ID) data,
but can significantly fail on Out-Of-Distribution (OOD) data. While developing
methods focus on improving OOD generalization, few attention has been paid to
evaluating the capability of models to handle OOD data. This study is devoted to
analyzing the problem of experimental ID test and designing OOD test paradigm to
accurately evaluate the practical performance. Our analysis is based on an
introduced categorization of three types of distribution shifts to generate OOD
data. Main observations include: (1) ID test fails in neither reflecting the actual
performance of a single model nor comparing between different models under OOD
data. (2) The ID test failure can be ascribed to the learned marginal and
conditional spurious correlations resulted from the corresponding distribution
shifts. Based on this, we propose novel OOD test paradigms to evaluate the
generalization capacity of models to unseen data, and discuss how to use OOD
test results to find bugs of models to guide model debugging.

model and experimental analysis of soap film filter
Learning More...
As for the soap film filter which is widely used today,
there is no corresponding quantitative analysis research
, which leads to the coarse model used
in some theoretical studies, and the conclusions obtained are
quite different from the actual results. In this paper,
two simulate models of solid passing through soap
film are established by quantitative analysis on the basis
of previous work. The final experimental results fit well
with the theory, which is of certain significance to the
analysis of practical problems and provides a certain theoretical
basis for the subsequent study of more complex problems and more
accurate analysis.

Based on Diversification Measure_ Application in Portfolio Strategy of Chinese Biopharmaceutical Industry
Learning More...
We study and explore the application the latest diversification measure of portfolio based on Rao’s Quadratic Entropy. We improve the previous model and propose an algorithm that can help to apply diversification measure to practice and improve the return performance of the portfolio model. In addition, our experiment focuses on the application of diversification measure to the portfolio strategy research in China's biopharmaceutical industry. The COVID-19 in 2020 is undoubtedly a global and declared health emergency. Currently, a lot of work is devoted to studying the impact of COVID-19 on the stock market. Our research on investment strategy from the perspective of diversification measure and portfolio optimization is innovative to some extent.
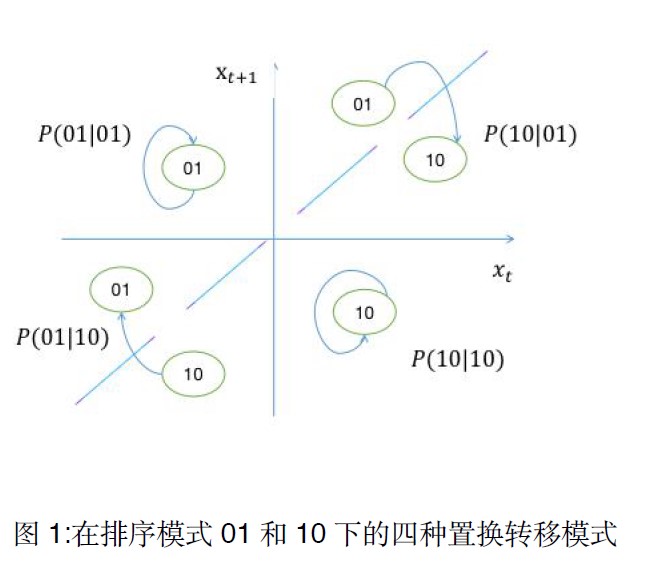
Permutation Transition Entropy: A new method of measuring the dynamical complexity of non-stationary time series
Learning More...
In this paper, we apply the method of Permutation Transition Entropy, which quantifies the
Markov states transition between adjacent permutations, to measure the dynamical complexity
of non-stationary time series. This method can capture the change of states trajectory of the
underlying system by quantifying the Markov states transition between adjacent permutations.
Unlike many traditional methods which usually measure the static complexity, the new
method of permutation transition entropy(PTE) is able to identify the dynamical complexity
with respect to the temporal structure change of the time series. By numerical analyses, we
show that the PTE can give new information while other methods, like the permutation
entropy (PE), cannot. We apply the PTE method to the financial time series, and find the
existence of the momentum effect in the daily closing price and the daily trading volume of
NASDAQ Composite Index. It indicates that the dynamical complexity of the index is lower
than that of the purely random time series. The forthcoming state of the daily closing price is,
therefore, a bit regular, which can be used for prediction. While the logarithm return shows
very similar PTE values with those of the purely random time series, which correspond to
high dynamical complexity. Furthermore, with multiscale analysis towards PTE, it turns out
that under the same embedding dimension, the series with higher time-scale are more
deterministic and represents more obvious momentum effect.
